
![]()
![]()
Standard Suite
Extensions & Plugins
Power Suite
Apps & Tools

Character reordering, contextual shaping, ligatures, positioning adjustments...##@$! Rendering complex Unicode scripts can be complex indeed. Except that D-Type Text Layout Extension makes it simple!
30-Day Evaluation
(Windows, Mac, Linux)![]()
![]()
![]()

Release 9.0
See What's New
Commonly used scripts such as Latin, Greek or Cyrillic are easy to display. All you need to do is render their characters in a simple linear progression from left to right and the resulting text is correctly displayed. Unfortunately, not all world's scripts are that simple. Many scripts, just to be displayed correctly, require special processing such as character reordering, contextual shaping, ligatures, positioning adjustments etc. These scripts are also known as complex scripts. Arabic, Indic and Thai are among those scripts. And even Latin scripts often use ligatures and various types of positioning adjustments (e.g. kerning) to enhance the appearance of displayed text.
The Unicode Standard alone does not help software developers with the task of laying out text. Unicode deals with the units of textual content (characters) and provides a good solution for the computer representation, storage and interchange of text. However, Unicode does not deal with the units of textual display (glyphs) and does not provide a solution to the problem of actual text layout, shaping and advanced typography. Obviously, a global, efficient and portable Unicode based text layout/shaping engine is necessary to help developers with this quite challenging task.[1]
To better understand the problems that layout/shaping engines must overcome, here are just some of the complications associated with the display of various world's scripts:
Directionality — Arabic and Hebrew are read from right to left. Consequently, the order of characters differs in presentation from storage. Character positioning, cursor movement and text selection in bidirectional context (the context in which left-to-right and right-to-left text runs coexist) is typically the biggest challenge to overcome. The characters are not laid out in a simple linear progression from left to right. In other words, the logical order of characters (the order in which the user enters text as a sequence of keystrokes) can be different from the visual order (the order in which glyphs are represented to the user)

Contextual Forms — Arabic scripts are not only read from right to left; they also require special processing necessary to display contextual forms properly. For example, the visual appearance of a character in Arabic scripts can change greatly depending on its position within a word and the characters that surround it. Most (but not all) characters have four different visual forms: isolated (when the character is alone), initial (beginning of a word), middle (within the word) and final (end of word).[2] This means that layout/shaping engines must not only shape those forms properly but also detect word boundaries within a given run of text.[3]

Ligatures — With Latin, Greek, Cyrillic and even Chinese/Korean/Japanese scripts, there is often a direct one-to-one mapping between a character and its glyph. However, in Arabic, Indic and other complex scripts, several characters can combine together to create a whole new glyph. These special glyphs are then called ligatures. Although Latin scripts can also make use of ligatures, most Latin ligatures are optional and designed to improve the aesthetic appearance of certain character combinations. However, in Arabic and many other complex scripts, certain ligatures are mandatory. In those cases it is unacceptable to present certain character combinations without using the appropriate ligature.
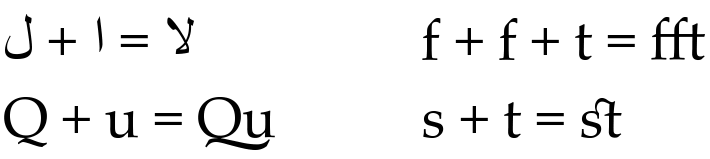
Glyph Reordering — The South Asian family of scripts (Indic) exhibit rendering complications that are not found in any other script. Letters are drawn in a different order from that in which they are typed or stored in memory, glyphs are inserted or rearranged and complex ligatures are formed. The actual amount of pre-processing necessary to convert a series of Unicode Devanagari characters into a series of glyphs is extensive. It should therefore come as no surprise that the Unicode Standard had to dedicate more than twelve pages just describing the proper processing of Devanagari characters.
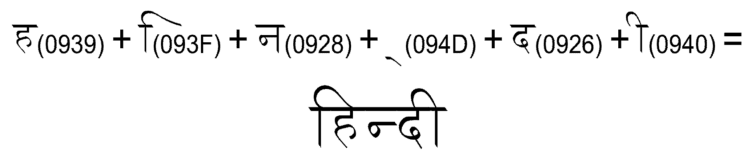
Multiple Code Points — The difficulty with contextual shaping is that a given character, for all of its various glyph forms, usually has only one defined code point in the Unicode Standard. Similarly, ligatures often do not have a Unicode code point.[4] It is the responsibility of the layout/shaping engine to determine, at run time depending on the context, the appropriate visual form of each character in the text.
D-Type Text Layout Extension thanks to the underlying HarfBuzz text shaping engine solves all of these problems in a simple and straightforward way. All complex script rendering is done in a uniform and consistent manner. The application is responsible for supplying to the Text Layout Extension an array of Unicode character codes in reading or logical order while the extension returns an array of glyphs to display in the correct visual order along with the coordinates necessary to properly position those glyphs and, additionally, character indices to map each glyph back to the input text array. Then, these positioned glyphs can be very easily rendered using D-Type Font Engine.
The benefit of this approach is that software developers do not have to be familiar with various complex scripts or any of the shaping rules that might be applicable to each script. Regardless of the script, the Text Layout Extension is always utilized in the same consistent way. It is only important to be aware of the following basic concepts:
The Text Layout Extension, or more precisely the underlying HarfBuzz text shaping engine, is designed to process a sequence of Unicode characters which is in a single font, script and direction. Developers can use the Unicode bidirectional algorithm built into the Text Layout Extension to determine the direction of the text or give the user direct control over bidirectional text layout.
The sequence of input characters is always passed to the Text Layout Extension in reading or logical order.
Developers should not assume a simple one-to-one mapping between input characters and output glyphs. In other words, the size of the resulting glyph array can be (and with complex scripts usually is) different than the size of the input Unicode character array.
When it is necessary to map output glyphs back to the initial sequence of input characters (e.g. for cursor movement and text selection), developers should use the returned array of character indices.
As mentioned above, D-Type Text Layout Extension internally relies on the HarfBuzz text shaping engine, a popular open source portable and platform independent layout engine capable of shaping many complex Unicode scripts including Arabic, Bengali, Devanagari, Gujarati, Gurmukhi, Han, Hebrew, Kannada, Malayalam, Oriya, Tamil, Telugu and Thai. The HarfBuzz text shaping engine uses layout tables found in font files and the knowledge of generic script shaping rules to lay out complex scripts.
D-Type Text Layout Extension takes care of all the font specific tasks and interaction with the HarfBuzz text shaping engine. Software developers can now use one simple extension to display all supported complex scripts without the need to write their own font access interfaces. D-Type Text Layout Extension is an extension of D-Type Font Engine that makes it possible to easily render complex scripts, hiding from the developer all the complexity associated with the text shaping process and the need to interface with the HarfBuzz text shaping engine directly.
For software developers who use or plan to use D-Type rendering technology, D-Type Text Layout Extension brings the following benefits:
The most recent D-Type Text Layout Extension includes HarfBuzz text shaping engine 3.2.0 that was released on December 11, 2021. As new HarfBuzz text shaping engine releases become available, the Text Layout Extension will be updated to support the most recent version.
________________